
目次
- はじめに
- セルフホスト(?)しよう
- WASMでエンコーダーを作る
- WASMバイナリの作成
- Zigでエンコーダーを再実装する
- JSからWASMを呼び出す
- エンコーダーをエンコードする
- ベンチマーク
- WASMの最適化
- まとめ
- PR
- 関連記事
はじめに
少し前、ふざけ半分で作ったBase8192というエンコーディングがあります。こんな感じです。
入力: What is base8192?
Base8192: 卶晡啂幩唲幢吗慥冃弹儣洀等
Base64: V2hhdCBpcyBiYXNlODE5Mj8=
Base8192は漢字を利用することで、Base64と比較して文字数(≠バイト数)を抑えることができます。上記の例では、Base64が24文字必要なのに対し、Base8192はわずか13文字で済みます。
仕組みに興味がある方は、GitHubのリポジトリのREADMEに詳細が書いてあります。
https://github.com/karintomania/Base8192
こいつをとりあえず実装して期待通りに動くことは確認したのですが、ふと思いました。ユーザーが入力したテキスト以外もエンコードしてみたいと。
セルフホスト(?)しよう
コンパイラの世界には、自作したコンパイラで、そのコンパイラ自身のソースコードをコンパイルするのがマイルストーンになっているそうです。
これはセルフホストと呼ばれます。
私は自分のエンコーディングでも同じようなことをやってみたくなりました。つまり、エンコーダーをそのエンコーダー自身でエンコードするということです。
WASMでエンコーダーを作る
Base8192の最初の実装は、実際に動くデモサイトを作りたかったのでJavaScriptで書きました。
デモサイト:https://karintomania.github.io/Base8192/
新しいセルフエンコードされたエンコーダーもこのサイトで使えるようにしたいのですが、ブラウザで直接実行できるJavaScriptをわざわざエンコードして載せるのは、あまり意味がありません。
そこで、ブラウザでも動くもう一つのランタイム、WASM (WebAssembly) です。
コード内にWASMバイナリを含める方法はいくつかありますが、バイナリをエンコードして、JS側でデコードして使うという流れは、今回のユースケースにぴったりなはずです。
WASMバイナリの作成
このチャレンジを始めるまで、私はWASMについて詳しく知りませんでした。調べてみると、さまざまな言語(JSでもできるらしい)をWASMにコンパイルできるようです。
今回、私は Zig を選択しました。単純に最近触っていて楽しかったのと、WASMのサポートが手厚そうだったからです。
Moonbitという言語も面白そうで迷ったのですが、これ以上一度に新しい言語を増やすと大変なことになるので、浮気したい衝動を抑えてZigに決めました。
プロジェクトの構成図はこんな感じです。
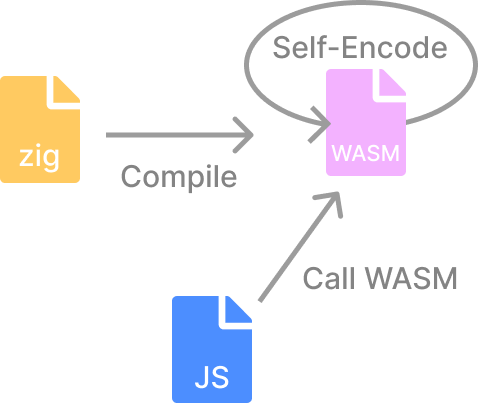
Zigでエンコーダーを再実装する
JavaScriptとZigで同じロジックを書くのは、結構勉強になりました。
この2つの言語の特徴は正反対で、かたやJSはガベージコレクションありの動的型の高級言語ですが、Zigは手動メモリ管理を行う静的型の低レベル言語です。
ただ驚いたことに、コードの量はそれほど変わりませんでした。JS(base8192.js)のコアロジックが288行なのに対し、Zig(base8192.zig)は258行(テストコードを除く)でした。
二度目の実装でロジックが洗練されたこともあると思いますが、低レイヤーなZigはもっとコードが長くなるかと思っていました。Zigのシンプルな構文のおかげでコンパクトに収まったようです。
JSからWASMを呼び出す
次に、WASMで定義したエンコード/デコード関数をJSから呼び出します。
ここで注意が必要なのは、WASM関数はJSに対してプリミティブな型、つまり数字くらいしか返せないという点です。
エンコード関数は文字列を返したいし、デコード関数は構造体を返したいのですが、どちらも直接はサポートされていません。
なので、文字列を返したいときにはまずWASM側のメモリに符号なし8ビット整数(u8)の配列として文字列を格納します。そして、JS側がWASMメモリのどこから、何文字分読めばいいかを把握できるように、そのアドレスと長さを伝える必要があります。

関数は1つの値しか返せないので、これは少し工夫が必要です。
素直な解決策は、ポインタを返す関数と長さを返す関数の2つを作ることです。Base8192のエンコードの場合、出力の長さは入力サイズから計算できるので、これでもいけます。
1 | fn getEncodeResultLen(inputLength: u32) u32 { |
しかし、デコードの場合はそうではありません。Base8192は自己同期する仕組みを持っていて、無効な文字列を検出するとスキップして次の有効なデータまで飛ばすため、実際にデコードが終わるまで最終的な出力の長さが確定しないからです。
そこで今回は、文字列の先頭にその長さを付与するようにしました。
関数は長さのプレフィックスがついた文字列へのポインタを返します。JS側は最初の4バイト(32ビット)を読み取って長さを把握し、5バイト目からその長さ分だけ文字列として読み取ります。

さて、デコード関数では、デコード結果の文字列と検出されたエラーのインデックスを持つ構造体返したいところです。
1 | { |
まあ、先ほどのように何バイト目がどの情報を持つ、みたいなこともできるのですが、めんどくさいのでJSON文字列として返し、その先頭に長さを付けることにしました。
JSON.parse() を走らせる分、JS側で多少のパフォーマンス低下はありますが、ペナルティが大したことなさそうなのと、実装の簡便さを優先してこの方法にしました。
エンコーダーをエンコードする
いよいよセルフエンコードです。
以下のコードでは、エンコーダーのバイナリファイルを読み込み、それを入力として encode_w_binary 関数を呼び出しています。
1 | async function encode_self() { |
そして、完成したのがこちらです。encoder.js に結果が格納されました(10,000文字以上ありますが、なんとかスクリーンショットに収めました)。

素晴らしいですね😊
実際のファイルはGitHubで見ることができます:encoder.js (raw)
ベンチマーク
パフォーマンス重視でWASMにしたわけではありませんが、やはりどれくらい速くなったかは気になります。2MBのCSVファイルを使って、エンコードにかかる時間を測定しました。
| 速度 (ms) | メモリ使用量 (MB) | |
|---|---|---|
| JS | 220 | 187 |
| WASM | 658 | 142 |
※メモリ使用量は time コマンドの Maximum resident set size から取得。
なんと、JSの方が早い。。。!しかも3倍近く。。。
同じテストを何度か試しましたが変わりませんでした泣。エンコードのような処理は、JSのJITがうまく機能するのかもしれません。
メモリ使用量は予想通りWASMの方が低かったです。
WASMの最適化
苦労して作ったWASMがJSより遅いという事実が受け入れられずにいたところに笑、Zigにはビルドの最適化オプションがあることを思い出しました。
Zigにはビルド時の最適化オプションがいくつか用意されています。
- Debug: デバッグ情報を残す
- Fast: 実行速度優先
- Small: バイナリサイズ優先
- Safe: メモリ安全性優先
最初は、デモサイトのロードを速くするためにSmallを使っていましたが、ベンチマークにはFastを使うことにしました。
Fastオプションを適用した結果がこちらです。
| 速度 (ms) | メモリ使用量 (MB) | |
|---|---|---|
| JS | 220 | 187 |
| WASM (small) | 658 | 142 |
| WASM (fast) | 183 | 140 |
約350%の高速化(658ms → 183ms)に成功し、無事にJSより早くエンコードできるようになりました!
まとめ
Base8192に興味を持ってくださった方は、こちらのデモサイトで遊んでみてください。今回作成したWASMバイナリが動いています。
https://karintomania.github.io/Base8192/
ところでこんなことをして何の意味があるのか?と思われるかもしれません。
Base8192がBase64に取って代わることは筆者自身もないと思っています笑。しかし、独自のエンコーディングを作成し、それをセルフエンコードする過程で、エンコーディングの仕組みやWASM、そしてZigを通じた低レイヤーの世界について多くを学ぶことができました。なんかこういう無意味かもしれないけど面白いコードを書けたのは良かったなと思います。
それじゃ今日はこの辺で。
PR
エンジニアならドメインのひとつやふたつ、持っておきたいですよね。ドメイン取得にはお名前ドットコムがおすすめです。
関連記事
こちらの記事もおすすめです。