
目次
背景
こんにちは。 かりんとうマニア(@karintozuki)です。
皆様、業務自動化してますか。(唐突
ありがちな業務としてPDFの読み取りがあるかと思います。
今日はPDFからテーブルの値を抽出できるTabulaというツールを紹介します。
Tabulaとは?
オープンソースのPDFからテーブルの値を抽出するソフトです。
値を抽出するといってもOCR(画像の読み取り)ではなく、
あくまでもテキストとして認識できるデータを対象としています。
このツールの良いところは、
色々な方法で実行が可能で、要件にそった利用方法を選ぶことができます。
Tabulaの実行方法には以下の三つの方法があります。
- GUI
- コマンドライン
- Java、Pythonなど各種言語のAPI
サクッと一、二枚を抽出するならGUI、
大量のPDFを自動で読み取る際にはコマンドラインからの実行か
Javaなどのプログラミング言語から呼び出して使用できます。
この記事では三つの使用方法をサクッと紹介します。
GUIでの実行
GUIではブラウザから直感的にテーブルを読み取ることができます。
また、このGUIで作成したテンプレートを、
他の方法でも利用するので、とりあえずこのステップはできるようにしておいてください。
Tabulaのダウンロード
Tabulaのダウンロード方法です。
Windowsでの方法を書いてますが、
Macでも大差ないかと思います。
以下のリンクからZipをダウンロードします。
https://tabula.technology/
こちらを任意のフォルダに解凍するだけで
利用可能になります。
簡単ですね。
Tabulaの利用法
それでは先ほどダウンロードしたTabulaを実行します。
解凍したフォルダにあるtabula.exeを起動します。
コマンドプロンプトが立ち上がり、
しばらくするとブラウザが立ち上がります。
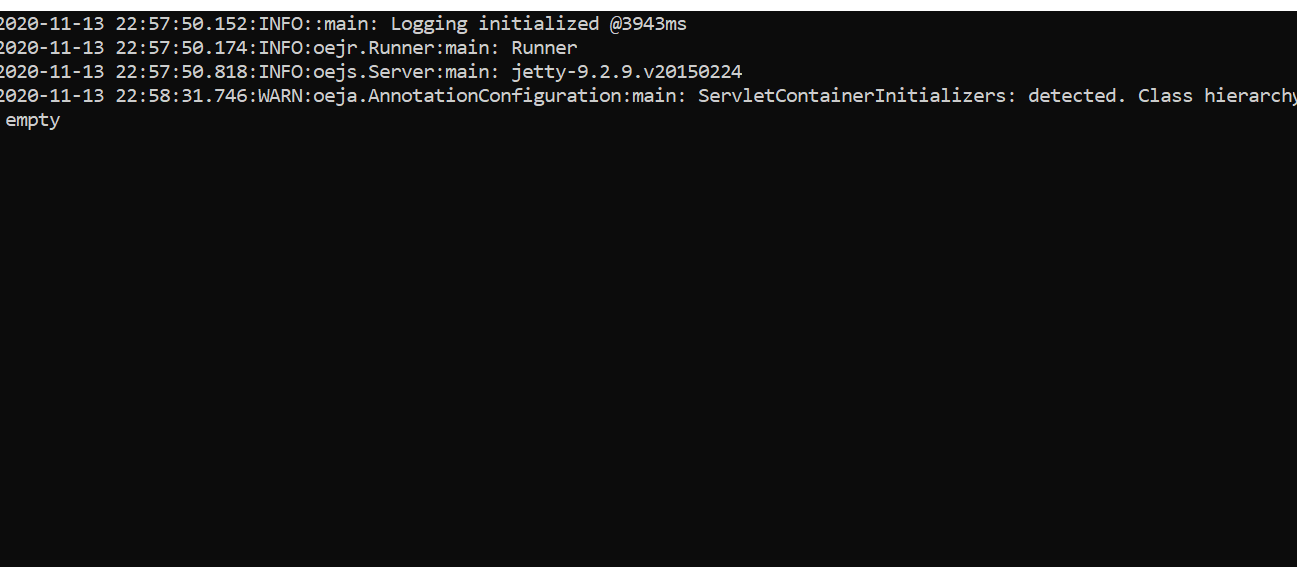
BrowseボタンからローカルにあるPDFファイルを指定します。
今回はテストとして以下のPDFを使ってみます。
https://github.com/tabulapdf/tabula-java/blob/master/src/test/resources/technology/tabula/20.pdf
importボタン押下でPDFを読み込みます。
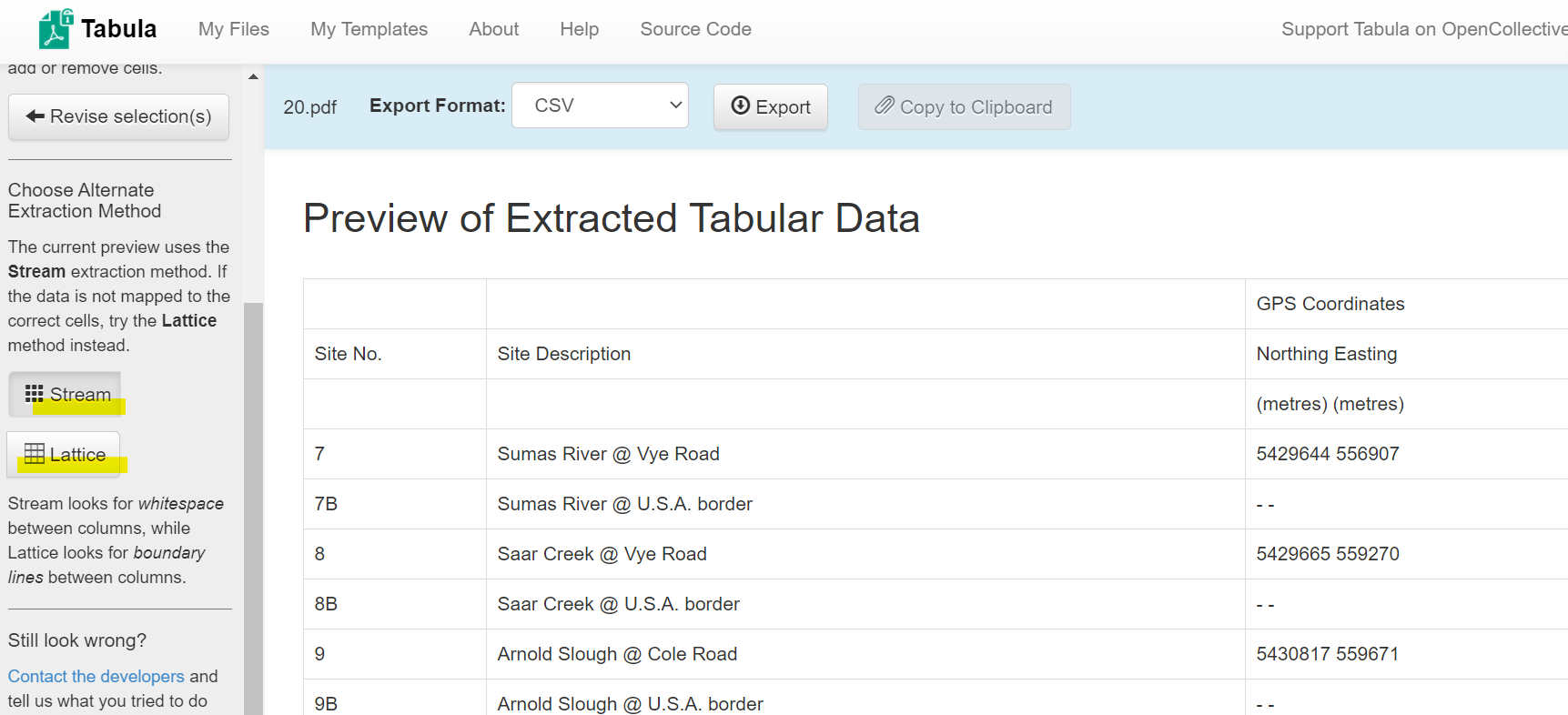
読み込みが完了したらテーブルの範囲を指定します。
Preview & Export Extracted Dataボタン押下で抽出を実行します。
読み込めたみたいですね。
この状態からCSVやJSONに出力が可能です。
Templateの作成
これ以降の操作の下準備として、
今回取得したテーブルの範囲をテンプレートとして保存しておきます。
My Templateタブからダウンロードします。
こんな感じのJSONになっています。
これらのx1,x2,y1,y2をこの後の自動化のステップで使用していきます。
1 | [ |
コマンドラインからの実行(tabula-java)
Tabulaはコマンドで実行することも可能です。
コマンドライン用のツールがあるので、
以下からjarファイルをダウンロードします。
https://github.com/tabulapdf/tabula-java/releases
適当な場所に配置して以下のコマンドを叩きます。
今回は簡単のためjarとPDFを同じ場所に配置しています。
また、ここで先ほど取得したjsonの座標情報を使用します。
1 | java -jar ./jarのパス/tabula-0.9.0-jar-with-dependencies.jar -p all -a $y1,$x1,$y2,$x2 -o {アウトプットのファイルパス} {対象PDFのパス} |
CSVが出力されます。

Javaライブラリ(tabula-java)の利用
tabulaはJavaのプログラムからも使用できます。
今回はGradleなどを使ったプロジェクトからライブラリを呼び出す場合を紹介します。
Gradle
repositoryにmavenCentralを追加します。
1 | repositories { |
dependenciesにtabulaを追加します。
1 | dependencies { |
実装
以下の関数でpdfを抽出してCSVに出力できます。
1 | public void extractPdf(){ |
PDFを読み込むアルゴリズムには、
BasicExtractionAlgorithmと
SpreadsheetExtractionAlgorithmがあります。
BasicExtractionAlgorithmは余白をみる、
SpreadsheetExtractionAlgorithmは罫線をみることで
テーブルを認識しているそうです。
GUI版では以下の箇所に対応しているので、どちらのメソッドが良いかは
GUIで試してみると良いと思います。
この例ではCSVに出力したいので、CSVWriterクラスを利用していますが、
他にもJSONでの出力用にJSONWriterクラスなども用意されています。
また、PDFのテーブル範囲を指定する処理をUtilとして
別クラスに切り出しています。
こちらは本家のテスト用Utilクラスを参考にしました。
https://github.com/tabulapdf/tabula-java/blob/master/src/test/java/technology/tabula/UtilsForTesting.java
1 | package tablajava; |
実際に動かしてみたい人は以下のレポジトリに
ソースを格納したので、使ってみてください。
https://github.com/karintomania/JavaTabulaDemo
まとめ
今回はTabulaの使い方を紹介しました。
PDFを自動で読み取りたい要件があったときには
使ってみてください。
それじゃ今日はこの辺で。
関連記事
こちらの記事もおすすめです。
現役エンジニアが業務を自動化してきた手法7つ+αを紹介【Windows編】
PR
あなたの会社はあなたの技術を評価してくれていますか?
技術力を高めようと頑張っているのに、
技術が評価されないような会社にいたらそれは良い環境なのでしょうか?
エンジニアとして技術を高めたいのなら環境を選ぶことも大事です。
レバテックキャリア
エンジニアとして働いていて実務経験があるなら、
求人数の充実具合からレバテックキャリアがおすすめです。
IT転職ではデファクト・スタンダードですね。
▼レバテック キャリア 登録はこちら▼![]()
Tech Clips
Tech Clipsは年収500万以上&自社サービスを持った会社に特化した求人サイトです。
首都圏限定になってはしまいますが、
収入を増やしたい、自社サービスを持った企業への転職をしたい人におすすめです。